!.")
I am a Ph.D. student at McGill University and Mila – Quebec AI Institute, co-advised by Prof. Doina Precup and Prof. Xiao-Wen Chang. My research focuses on continual reinforcement learning, aiming to develop AI systems that can learn and adapt in non-stationary environments. I am also a Board Member of ContinualAI, a nonprofit organization advancing research in continual learning. I co-organize the Mila Tea Talk, a weekly seminar series at Mila.
Previously, I completed my M.Sc. in Electrical and Computer Engineering at McGill and Mila, under the supervision of Prof. Narges Armanfard and Prof. Samira Ebrahimi Kahou, where I worked on anomaly detection. I also hold a B.Sc. in Electrical and Computer Engineering, with a Minor in Mathematics, from the University of Alberta.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 McGill University && Mila-Quebec AI InstituteSchool of Computer Science
McGill University && Mila-Quebec AI InstituteSchool of Computer Science
Ph.D. Student
Supervisors: Doina Precup, Xiao-Wen ChangSep. 2025 - present -
 McGill University && Mila-Quebec AI InstituteM.Sc. in Electrical and Computer Engineering
McGill University && Mila-Quebec AI InstituteM.Sc. in Electrical and Computer Engineering
Supervisors: Narges Armanfard, Samira Ebrahimi KahouSep. 2023 - Aug. 2025 -
 University of AlbertaB.Sc. in Electrical and Computer Engineering
University of AlbertaB.Sc. in Electrical and Computer Engineering
Minor in MathematicsSep. 2018 - Jun. 2023
Experience
-
Mila – Quebec AI Institute / Linarite AIScientist in ResidenceSep 2025 – Apr 2026
-
 ContinualAIBoard MemberMay 2024 - Present
ContinualAIBoard MemberMay 2024 - Present -
 Huawei Noah's Ark Lab, Montreal, CanadaResearcher InternJul. 2024 – Sep. 2024
Huawei Noah's Ark Lab, Montreal, CanadaResearcher InternJul. 2024 – Sep. 2024
Honors & Awards
-
Flight PS752 Commemorative Scholarship2025–2026
-
FRQNT Doctoral Research Scholarship2025–2029
-
GREAT Scholarship2025
-
FRQNT Master’s Research Scholarship2024–2025
-
McGill University Graduate Excellence Fellowship2023–2026
-
University of Alberta Academic Scholarship (×3)2019–2023
-
University of Alberta Dean’s Research Award (×2)2021, 2022
-
Graduated with Distinction, University of Alberta2023
News
Selected Publications (view all )
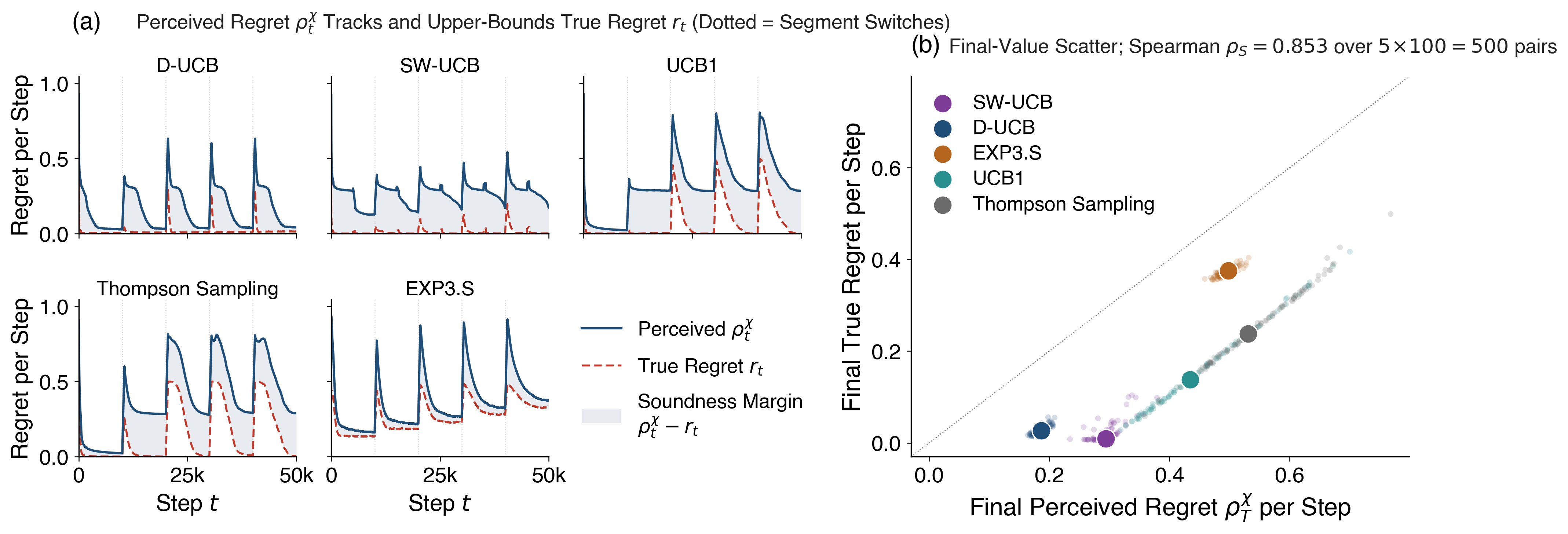
Perceived Regret: Evaluating Agents in Any World
Wesley Chung*, Zihan Wang*, Xiao-Wen Chang, David Meger, Doina Precup (* equal contribution)
Continual RL Workshop, Reinforcement Learning Conference (RLC) 2026
Continual reinforcement learning considers an agent that receives and learns from a stream of experience, aiming to maximize its accumulated reward. A fundamental problem is to evaluate such an agent using only its stream of experience, without assuming a particular structure of the world. We define an examiner that observes the same stream and, at every timestep, computes a perceived regret representing the agent's suboptimality gap from the examiner's perspective. We demonstrate empirically that perceived regret is a useful performance measure applicable to arbitrary streams of experience, and prove that no universal examiner can accurately assess all agents in any world, though specific modeling biases enable success in associated environments.
Perceived Regret: Evaluating Agents in Any World
Wesley Chung*, Zihan Wang*, Xiao-Wen Chang, David Meger, Doina Precup (* equal contribution)
Continual RL Workshop, Reinforcement Learning Conference (RLC) 2026
Continual reinforcement learning considers an agent that receives and learns from a stream of experience, aiming to maximize its accumulated reward. A fundamental problem is to evaluate such an agent using only its stream of experience, without assuming a particular structure of the world. We define an examiner that observes the same stream and, at every timestep, computes a perceived regret representing the agent's suboptimality gap from the examiner's perspective. We demonstrate empirically that perceived regret is a useful performance measure applicable to arbitrary streams of experience, and prove that no universal examiner can accurately assess all agents in any world, though specific modeling biases enable success in associated environments.
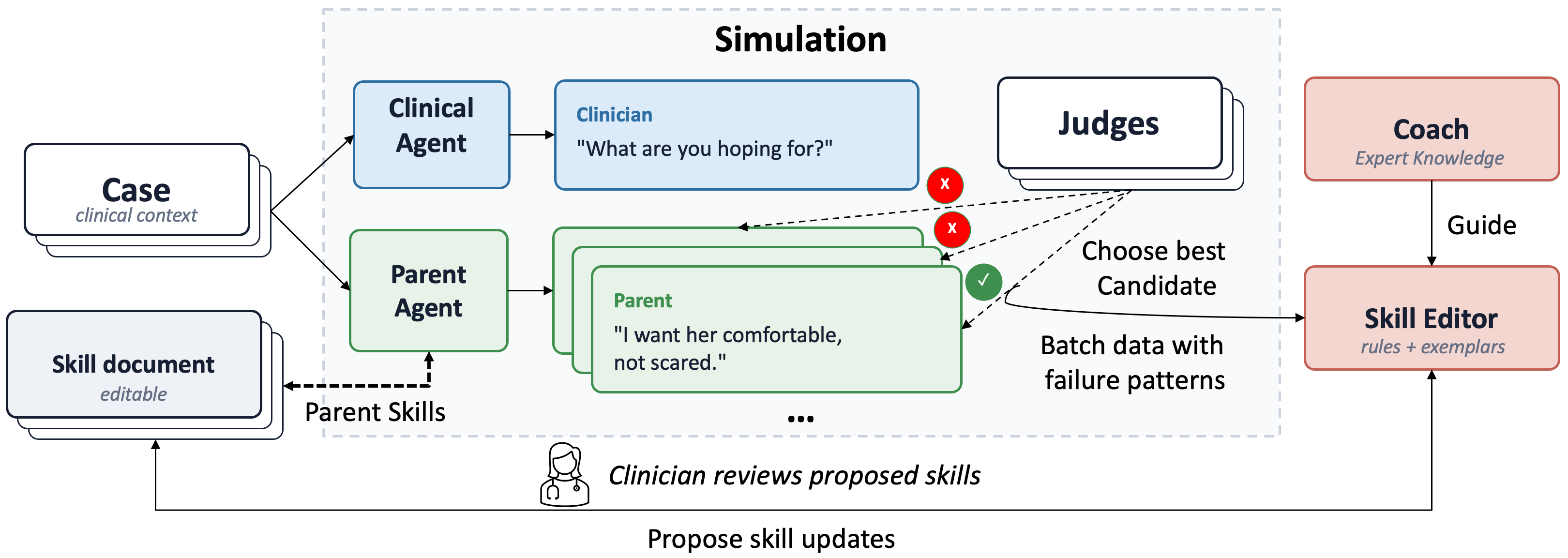
SIC-Agents: Benchmarking and Building Adaptive Simulator for Pediatric Serious Illness Communication Training
Zihan Wang, Anita Slominska, Rennie Bimman, Elizabeth Di Flumeri, Amanda Mayappo-Neeposh, Conall Francoeur, Tamara Ellen Carver, Xiao-Wen Chang, Doina Precup, Esin Darici Haritaoglu, Ismail Haritaoglu, Akshatha Arodi, Naomi Goloff
Under review at EMNLP 2026
Pediatric serious illness communication (SIC) is critically important, yet scalable communication training for clinicians remains limited. Compared with other dialogue simulation settings, pediatric SIC poses additional challenges, including multi-party interactions, response to parental distress, and strong dependence on feedback dynamics. In collaboration with educators and pediatric clinicians, we introduce the first benchmark suite and simulation framework tailored to pediatric SIC training. Our benchmarks, PitfallBench and DialogueBench, evaluate simulators both at the turn level and across full dialogues. We further propose SIC-Agents, a self-improving framework that generates a clinician-editable skill document to guide simulator behavior. Our experiments show that SIC-Agents outperforms static expert prompting. To support future research, we release our benchmarks and a training interface for parent simulation in pediatric SIC.
SIC-Agents: Benchmarking and Building Adaptive Simulator for Pediatric Serious Illness Communication Training
Zihan Wang, Anita Slominska, Rennie Bimman, Elizabeth Di Flumeri, Amanda Mayappo-Neeposh, Conall Francoeur, Tamara Ellen Carver, Xiao-Wen Chang, Doina Precup, Esin Darici Haritaoglu, Ismail Haritaoglu, Akshatha Arodi, Naomi Goloff
Under review at EMNLP 2026
Pediatric serious illness communication (SIC) is critically important, yet scalable communication training for clinicians remains limited. Compared with other dialogue simulation settings, pediatric SIC poses additional challenges, including multi-party interactions, response to parental distress, and strong dependence on feedback dynamics. In collaboration with educators and pediatric clinicians, we introduce the first benchmark suite and simulation framework tailored to pediatric SIC training. Our benchmarks, PitfallBench and DialogueBench, evaluate simulators both at the turn level and across full dialogues. We further propose SIC-Agents, a self-improving framework that generates a clinician-editable skill document to guide simulator behavior. Our experiments show that SIC-Agents outperforms static expert prompting. To support future research, we release our benchmarks and a training interface for parent simulation in pediatric SIC.
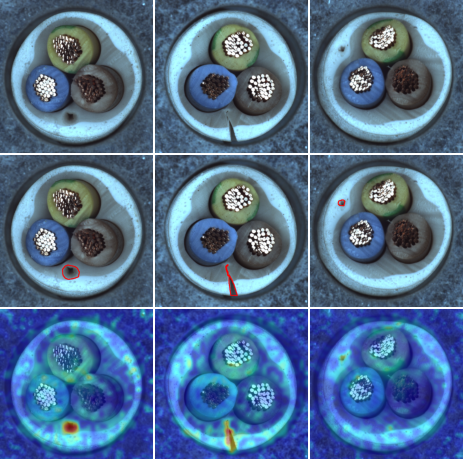
Zero-shot Anomaly Detection with Dual-Branch Prompt Learning
Zihan Wang, Samira Ebrahimi Kahou, Narges Armanfard
Proceedings of the British Machine Vision Conference (BMVC) 2025 Oral
Zero-shot anomaly detection (ZSAD) aims to identify and localize unseen defects without requiring any labeled anomalies, but existing methods struggle to generalize under domain shifts. We propose PILOT, a framework combining a dual-branch prompt learning mechanism with label-free test-time adaptation, enabling dynamic adaptation to new distributions using only unlabeled data. PILOT achieves state-of-the-art performance on 13 industrial and medical benchmarks for both anomaly detection and localization under domain shift.
Zero-shot Anomaly Detection with Dual-Branch Prompt Learning
Zihan Wang, Samira Ebrahimi Kahou, Narges Armanfard
Proceedings of the British Machine Vision Conference (BMVC) 2025 Oral
Zero-shot anomaly detection (ZSAD) aims to identify and localize unseen defects without requiring any labeled anomalies, but existing methods struggle to generalize under domain shifts. We propose PILOT, a framework combining a dual-branch prompt learning mechanism with label-free test-time adaptation, enabling dynamic adaptation to new distributions using only unlabeled data. PILOT achieves state-of-the-art performance on 13 industrial and medical benchmarks for both anomaly detection and localization under domain shift.
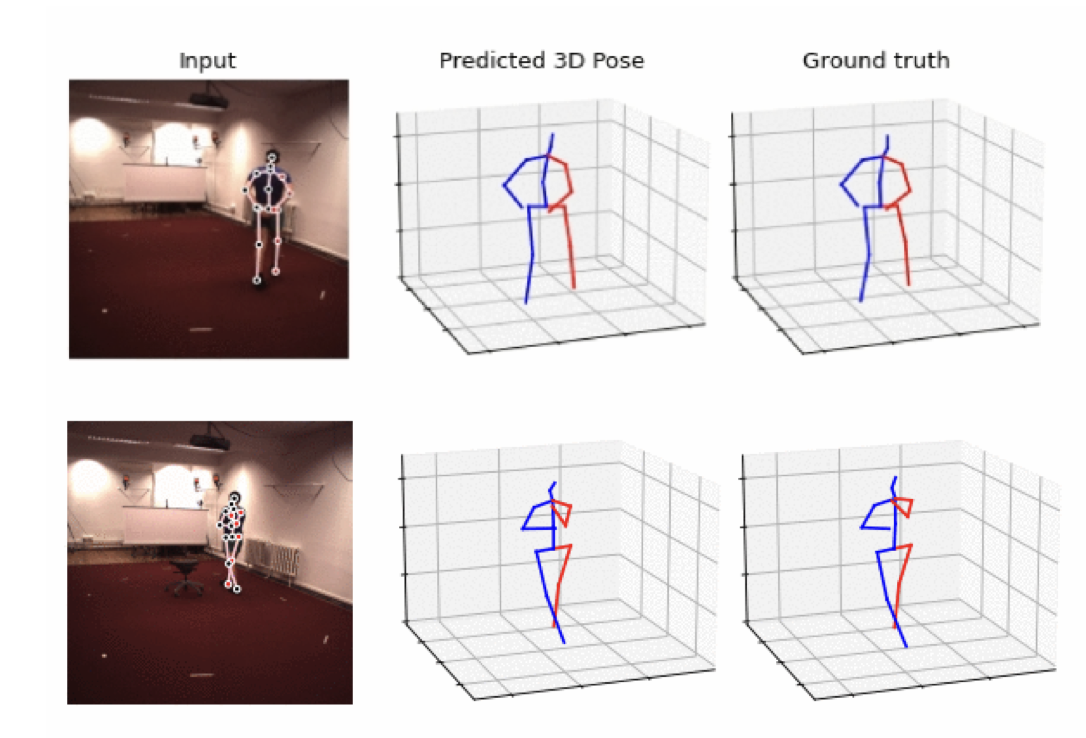
SPGNet: Spatial Projection Guided 3D Human Pose Estimation in Low Dimensional Space
Zihan Wang, Ruimin Chen, Mengxuan Liu, Guanfang Dong, Anup Basu
International Conference on Smart Multimedia 2022
We propose SPGNet, a method for 3D human pose estimation that integrates multi-dimensional re-projection into supervised learning. Our approach enforces kinematic constraints and jointly optimizes both 2D and 3D pose consistency, leading to improved accuracy. Experiments on the Human3.6M dataset show that SPGNet outperforms many state-of-the-art methods.
SPGNet: Spatial Projection Guided 3D Human Pose Estimation in Low Dimensional Space
Zihan Wang, Ruimin Chen, Mengxuan Liu, Guanfang Dong, Anup Basu
International Conference on Smart Multimedia 2022
We propose SPGNet, a method for 3D human pose estimation that integrates multi-dimensional re-projection into supervised learning. Our approach enforces kinematic constraints and jointly optimizes both 2D and 3D pose consistency, leading to improved accuracy. Experiments on the Human3.6M dataset show that SPGNet outperforms many state-of-the-art methods.