Submitted / Under Review
SIC-Agents: Benchmarking and Building Adaptive Simulator for Pediatric Serious Illness Communication Training
Zihan Wang, Anita Slominska, Rennie Bimman, Elizabeth Di Flumeri, Amanda Mayappo-Neeposh, Conall Francoeur, Tamara Ellen Carver, Xiao-Wen Chang, Doina Precup, Esin Darici Haritaoglu, Ismail Haritaoglu, Akshatha Arodi, Naomi Goloff
Under review at EMNLP 2026
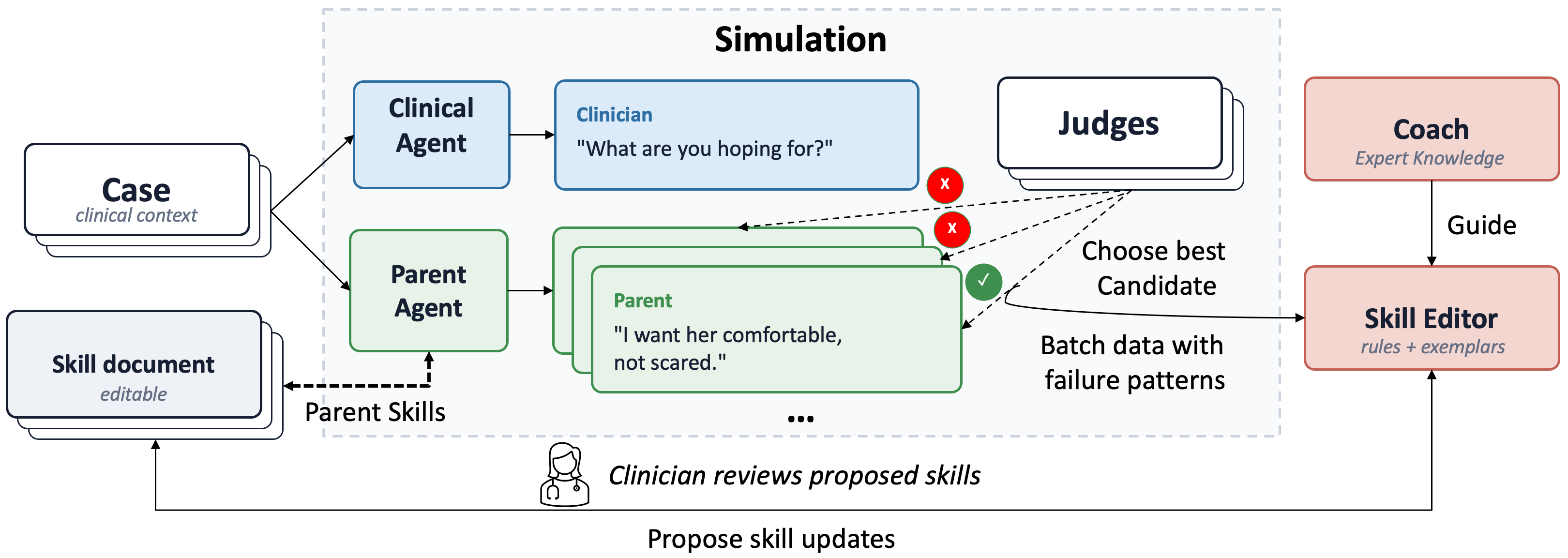
Pediatric serious illness communication (SIC) is critically important, yet scalable communication training for clinicians remains limited. Compared with other dialogue simulation settings, pediatric SIC poses additional challenges, including multi-party interactions, response to parental distress, and strong dependence on feedback dynamics. In collaboration with educators and pediatric clinicians, we introduce the first benchmark suite and simulation framework tailored to pediatric SIC training. Our benchmarks, PitfallBench and DialogueBench, evaluate simulators both at the turn level and across full dialogues. We further propose SIC-Agents, a self-improving framework that generates a clinician-editable skill document to guide simulator behavior. Our experiments show that SIC-Agents outperforms static expert prompting. To support future research, we release our benchmarks and a training interface for parent simulation in pediatric SIC.
SIC-Agents: Benchmarking and Building Adaptive Simulator for Pediatric Serious Illness Communication Training
Zihan Wang, Anita Slominska, Rennie Bimman, Elizabeth Di Flumeri, Amanda Mayappo-Neeposh, Conall Francoeur, Tamara Ellen Carver, Xiao-Wen Chang, Doina Precup, Esin Darici Haritaoglu, Ismail Haritaoglu, Akshatha Arodi, Naomi Goloff
Under review at EMNLP 2026
Pediatric serious illness communication (SIC) is critically important, yet scalable communication training for clinicians remains limited. Compared with other dialogue simulation settings, pediatric SIC poses additional challenges, including multi-party interactions, response to parental distress, and strong dependence on feedback dynamics. In collaboration with educators and pediatric clinicians, we introduce the first benchmark suite and simulation framework tailored to pediatric SIC training. Our benchmarks, PitfallBench and DialogueBench, evaluate simulators both at the turn level and across full dialogues. We further propose SIC-Agents, a self-improving framework that generates a clinician-editable skill document to guide simulator behavior. Our experiments show that SIC-Agents outperforms static expert prompting. To support future research, we release our benchmarks and a training interface for parent simulation in pediatric SIC.

From Connectivity to Rewards: Dense Reward Learning with Directed State Graphs
Shuyuan Zhang, Zihan Wang, Xiao-Wen Chang, Doina Precup
Under review at Transactions on Machine Learning Research (TMLR) 2026
Graph-based Goal-Conditioned Hierarchical Reinforcement Learning (GCHRL) typically uses the graph as a stochastic sampling tool rather than as an environmental model that encodes connectivity and state-accessibility information, which is particularly limiting in quasimetric environments where asymmetric state transitions challenge stable policy learning and path planning. We introduce a state connectivity model that predicts pairwise state-connectivity strength in asymmetric environments and transforms it into scalar auxiliary dense rewards that provide continuous guidance across hierarchical levels. Our framework, Graph-Guided Quasimetric Dense Reward (G2QDR), can be integrated into any existing GCHRL architecture; the connectivity model is implemented as a neural network trained on a directed state graph generated during exploration. Across a wide range of sparse-reward environments, G2QDR significantly enhances baseline GCHRL approaches with minimal computational overhead.
From Connectivity to Rewards: Dense Reward Learning with Directed State Graphs
Shuyuan Zhang, Zihan Wang, Xiao-Wen Chang, Doina Precup
Under review at Transactions on Machine Learning Research (TMLR) 2026
Graph-based Goal-Conditioned Hierarchical Reinforcement Learning (GCHRL) typically uses the graph as a stochastic sampling tool rather than as an environmental model that encodes connectivity and state-accessibility information, which is particularly limiting in quasimetric environments where asymmetric state transitions challenge stable policy learning and path planning. We introduce a state connectivity model that predicts pairwise state-connectivity strength in asymmetric environments and transforms it into scalar auxiliary dense rewards that provide continuous guidance across hierarchical levels. Our framework, Graph-Guided Quasimetric Dense Reward (G2QDR), can be integrated into any existing GCHRL architecture; the connectivity model is implemented as a neural network trained on a directed state graph generated during exploration. Across a wide range of sparse-reward environments, G2QDR significantly enhances baseline GCHRL approaches with minimal computational overhead.
2026
Unsupervised Continual Clustering via Forward-Backward Knowledge Distillation
Mohammadreza Sadeghi, Sareh Soleimani, Zihan Wang, Narges Armanfard
European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2026
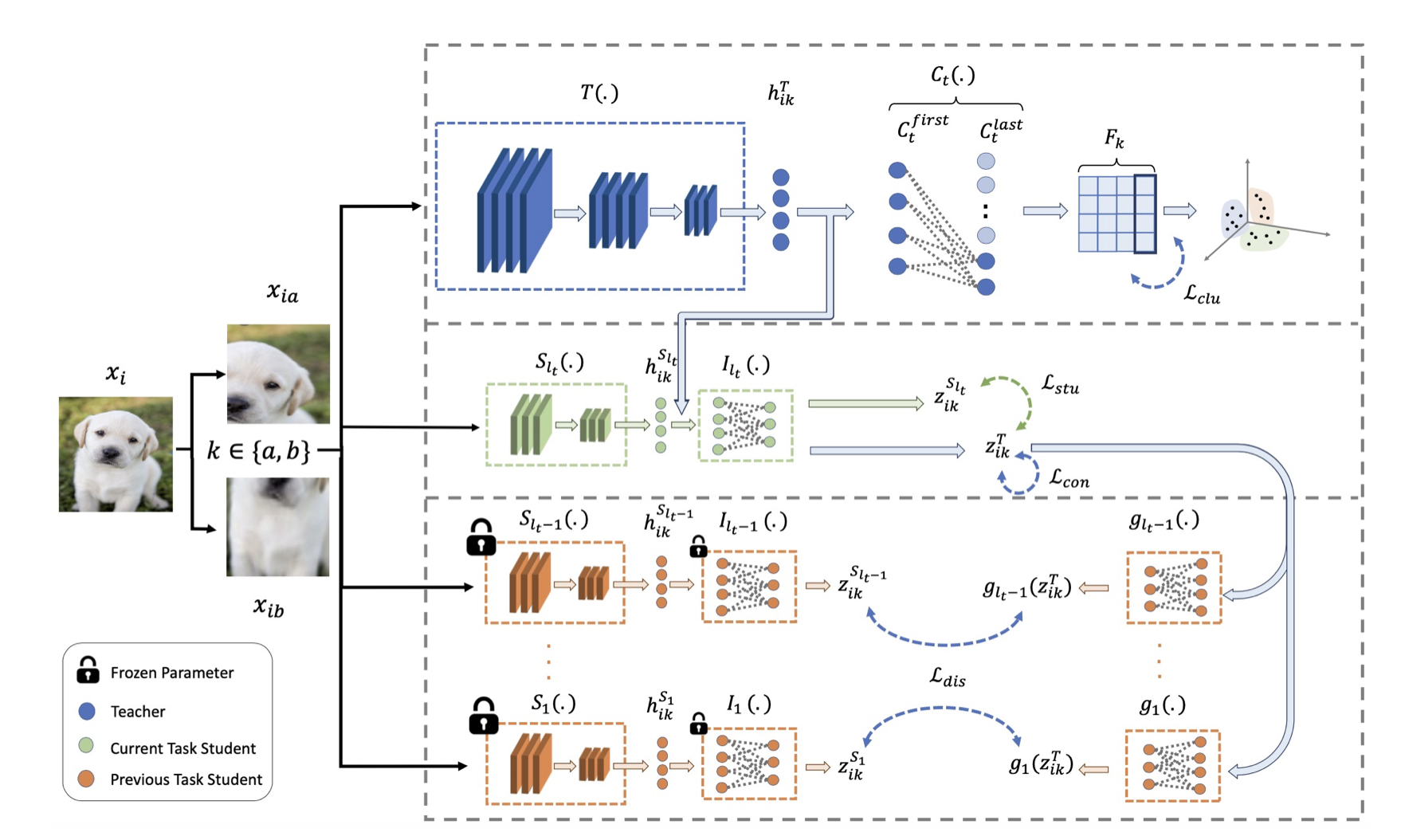
We introduce Unsupervised Continual Clustering (UCC) and propose Forward-Backward Knowledge Distillation for Continual Clustering (FBCC) to address catastrophic forgetting in unsupervised continual learning. FBCC leverages a teacher-student distillation framework with both forward and backward knowledge transfer to enhance memory efficiency and clustering performance. Experiments show that FBCC outperforms existing methods on continual clustering tasks, marking a significant advance for unsupervised continual learning.
Unsupervised Continual Clustering via Forward-Backward Knowledge Distillation
Mohammadreza Sadeghi, Sareh Soleimani, Zihan Wang, Narges Armanfard
European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2026
We introduce Unsupervised Continual Clustering (UCC) and propose Forward-Backward Knowledge Distillation for Continual Clustering (FBCC) to address catastrophic forgetting in unsupervised continual learning. FBCC leverages a teacher-student distillation framework with both forward and backward knowledge transfer to enhance memory efficiency and clustering performance. Experiments show that FBCC outperforms existing methods on continual clustering tasks, marking a significant advance for unsupervised continual learning.
GitChameleon 2.0: Evaluating AI Code Generation Against Python Library Version Incompatibilities
Diganta Misra*, Nizar Islah*, Victor May, Brice Rauby, Zihan Wang, Justine Gehring, Muawiz Sajjad Chaudhary, Antonio Orvieto, Eilif B. Muller, Irina Rish, Samira Ebrahimi Kahou, Massimo Caccia (* equal contribution)
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL) 2026
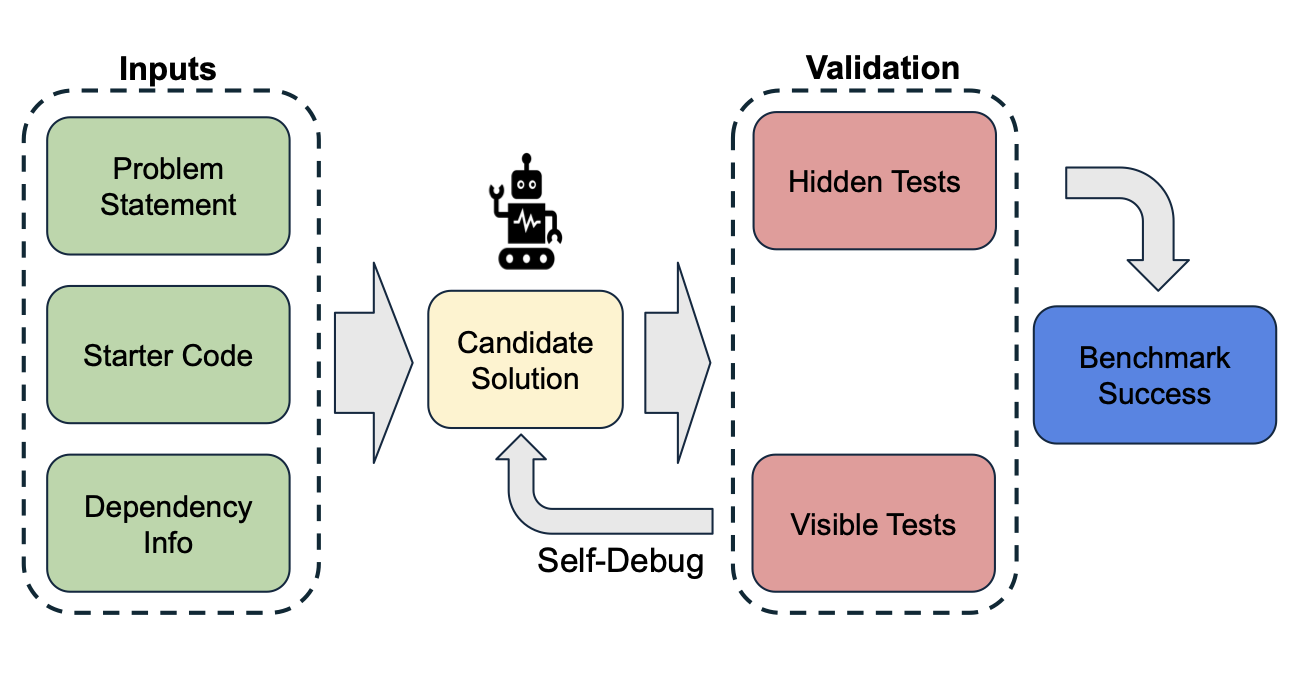
We present GitChameleon 2.0, a dataset of 328 Python code completion problems conditioned on specific library versions, each paired with executable unit tests for rigorous, execution-based evaluation. Our analysis reveals that state-of-the-art LLMs and code assistants struggle with version-conditioned code generation, achieving only 48–51% success rates. GitChameleon 2.0 provides a challenging benchmark to spur advances in adaptable and robust AI code generation.
GitChameleon 2.0: Evaluating AI Code Generation Against Python Library Version Incompatibilities
Diganta Misra*, Nizar Islah*, Victor May, Brice Rauby, Zihan Wang, Justine Gehring, Muawiz Sajjad Chaudhary, Antonio Orvieto, Eilif B. Muller, Irina Rish, Samira Ebrahimi Kahou, Massimo Caccia (* equal contribution)
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL) 2026
We present GitChameleon 2.0, a dataset of 328 Python code completion problems conditioned on specific library versions, each paired with executable unit tests for rigorous, execution-based evaluation. Our analysis reveals that state-of-the-art LLMs and code assistants struggle with version-conditioned code generation, achieving only 48–51% success rates. GitChameleon 2.0 provides a challenging benchmark to spur advances in adaptable and robust AI code generation.
Perceived Regret: Evaluating Agents in Any World
Wesley Chung*, Zihan Wang*, Xiao-Wen Chang, David Meger, Doina Precup (* equal contribution)
Continual RL Workshop, Reinforcement Learning Conference (RLC) 2026
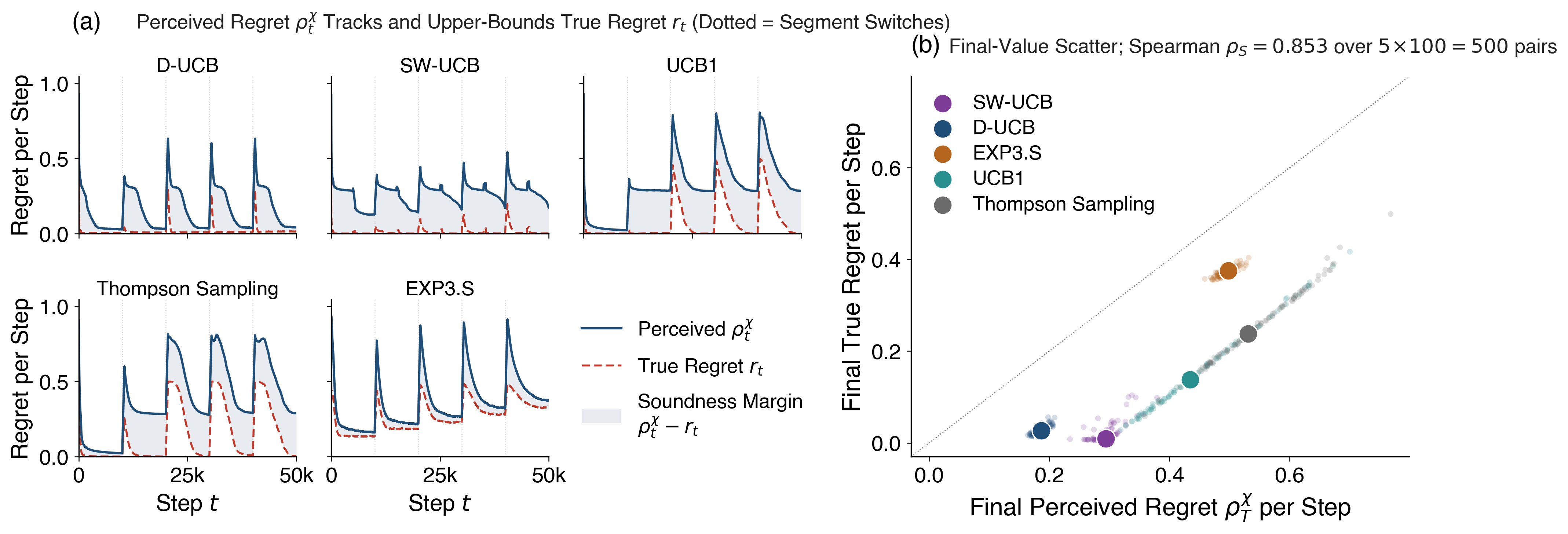
Continual reinforcement learning considers an agent that receives and learns from a stream of experience, aiming to maximize its accumulated reward. A fundamental problem is to evaluate such an agent using only its stream of experience, without assuming a particular structure of the world. We define an examiner that observes the same stream and, at every timestep, computes a perceived regret representing the agent's suboptimality gap from the examiner's perspective. We demonstrate empirically that perceived regret is a useful performance measure applicable to arbitrary streams of experience, and prove that no universal examiner can accurately assess all agents in any world, though specific modeling biases enable success in associated environments.
Perceived Regret: Evaluating Agents in Any World
Wesley Chung*, Zihan Wang*, Xiao-Wen Chang, David Meger, Doina Precup (* equal contribution)
Continual RL Workshop, Reinforcement Learning Conference (RLC) 2026
Continual reinforcement learning considers an agent that receives and learns from a stream of experience, aiming to maximize its accumulated reward. A fundamental problem is to evaluate such an agent using only its stream of experience, without assuming a particular structure of the world. We define an examiner that observes the same stream and, at every timestep, computes a perceived regret representing the agent's suboptimality gap from the examiner's perspective. We demonstrate empirically that perceived regret is a useful performance measure applicable to arbitrary streams of experience, and prove that no universal examiner can accurately assess all agents in any world, though specific modeling biases enable success in associated environments.
2025
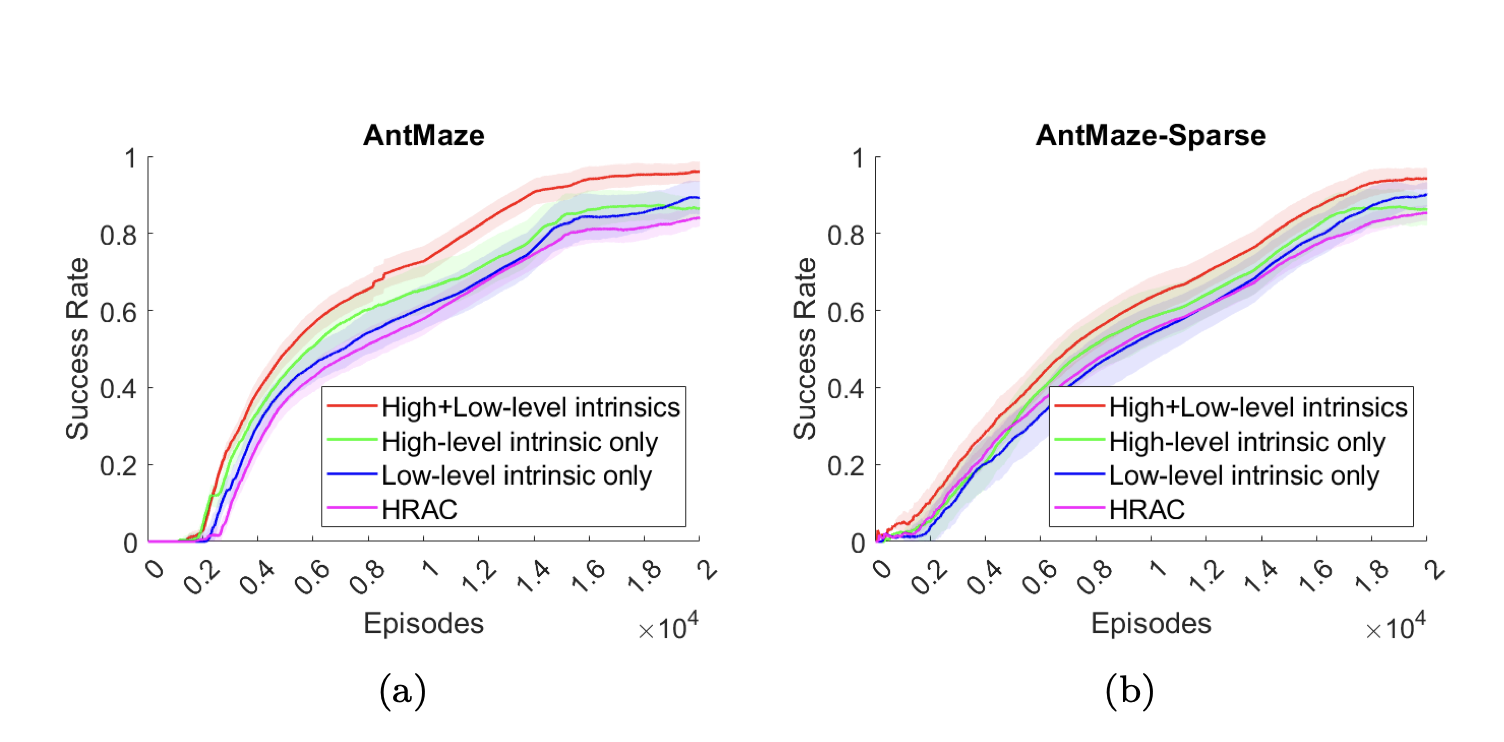
Incorporating Spatial Information into Goal-Conditioned Hierarchical Reinforcement Learning via Graph Representations
Shuyuan Zhang, Zihan Wang, Xiao-Wen Chang, Doina Precup
Transactions on Machine Learning Research (TMLR) 2025
We propose Graph-Guided sub-Goal representation Generation RL (G4RL), a method that incorporates a graph encoder-decoder into goal-conditioned hierarchical reinforcement learning (GCHRL) to address sample inefficiency and subgoal representation issues. G4RL leverages state graphs built during exploration to provide intrinsic rewards and enable effective evaluation of unseen states, without requiring domain-specific knowledge. Experiments demonstrate that G4RL consistently improves the performance of state-of-the-art GCHRL methods in both dense and sparse reward settings with minimal computational overhead.
Incorporating Spatial Information into Goal-Conditioned Hierarchical Reinforcement Learning via Graph Representations
Shuyuan Zhang, Zihan Wang, Xiao-Wen Chang, Doina Precup
Transactions on Machine Learning Research (TMLR) 2025
We propose Graph-Guided sub-Goal representation Generation RL (G4RL), a method that incorporates a graph encoder-decoder into goal-conditioned hierarchical reinforcement learning (GCHRL) to address sample inefficiency and subgoal representation issues. G4RL leverages state graphs built during exploration to provide intrinsic rewards and enable effective evaluation of unseen states, without requiring domain-specific knowledge. Experiments demonstrate that G4RL consistently improves the performance of state-of-the-art GCHRL methods in both dense and sparse reward settings with minimal computational overhead.
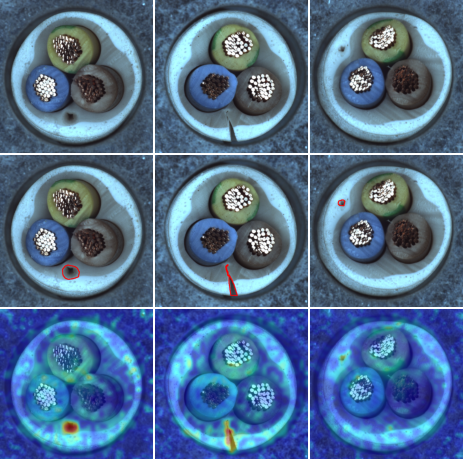
Zero-shot Anomaly Detection with Dual-Branch Prompt Learning
Zihan Wang, Samira Ebrahimi Kahou, Narges Armanfard
Proceedings of the British Machine Vision Conference (BMVC) 2025 Oral
Zero-shot anomaly detection (ZSAD) aims to identify and localize unseen defects without requiring any labeled anomalies, but existing methods struggle to generalize under domain shifts. We propose PILOT, a framework combining a dual-branch prompt learning mechanism with label-free test-time adaptation, enabling dynamic adaptation to new distributions using only unlabeled data. PILOT achieves state-of-the-art performance on 13 industrial and medical benchmarks for both anomaly detection and localization under domain shift.
Zero-shot Anomaly Detection with Dual-Branch Prompt Learning
Zihan Wang, Samira Ebrahimi Kahou, Narges Armanfard
Proceedings of the British Machine Vision Conference (BMVC) 2025 Oral
Zero-shot anomaly detection (ZSAD) aims to identify and localize unseen defects without requiring any labeled anomalies, but existing methods struggle to generalize under domain shifts. We propose PILOT, a framework combining a dual-branch prompt learning mechanism with label-free test-time adaptation, enabling dynamic adaptation to new distributions using only unlabeled data. PILOT achieves state-of-the-art performance on 13 industrial and medical benchmarks for both anomaly detection and localization under domain shift.
2023
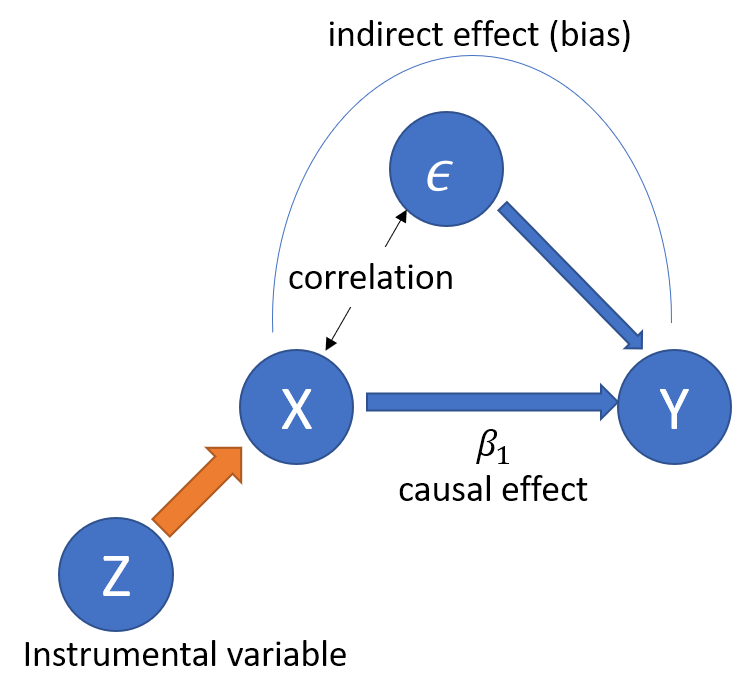
Instrumental Variables Matter: Towards Causal Inference Using Deep Learning
Kunhan Wu*, Zihan Wang*, Jingyi Zhao, Haodong Xu, Tianming Hao, Wenzhi Lin (* equal contribution)
Journal of Physics: Conference Series 2023
We implement DeepIV, a pioneering framework that combines deep learning and instrumental variables for causal inference, to predict the effect of educational background on annual income using real-world datasets. Our results show that DeepIV achieves causal effect predictions comparable to established causal inference models and performs on par with traditional supervised learning methods. This demonstrates DeepIV’s practical reliability for real-world causal inference tasks.
Instrumental Variables Matter: Towards Causal Inference Using Deep Learning
Kunhan Wu*, Zihan Wang*, Jingyi Zhao, Haodong Xu, Tianming Hao, Wenzhi Lin (* equal contribution)
Journal of Physics: Conference Series 2023
We implement DeepIV, a pioneering framework that combines deep learning and instrumental variables for causal inference, to predict the effect of educational background on annual income using real-world datasets. Our results show that DeepIV achieves causal effect predictions comparable to established causal inference models and performs on par with traditional supervised learning methods. This demonstrates DeepIV’s practical reliability for real-world causal inference tasks.
2022
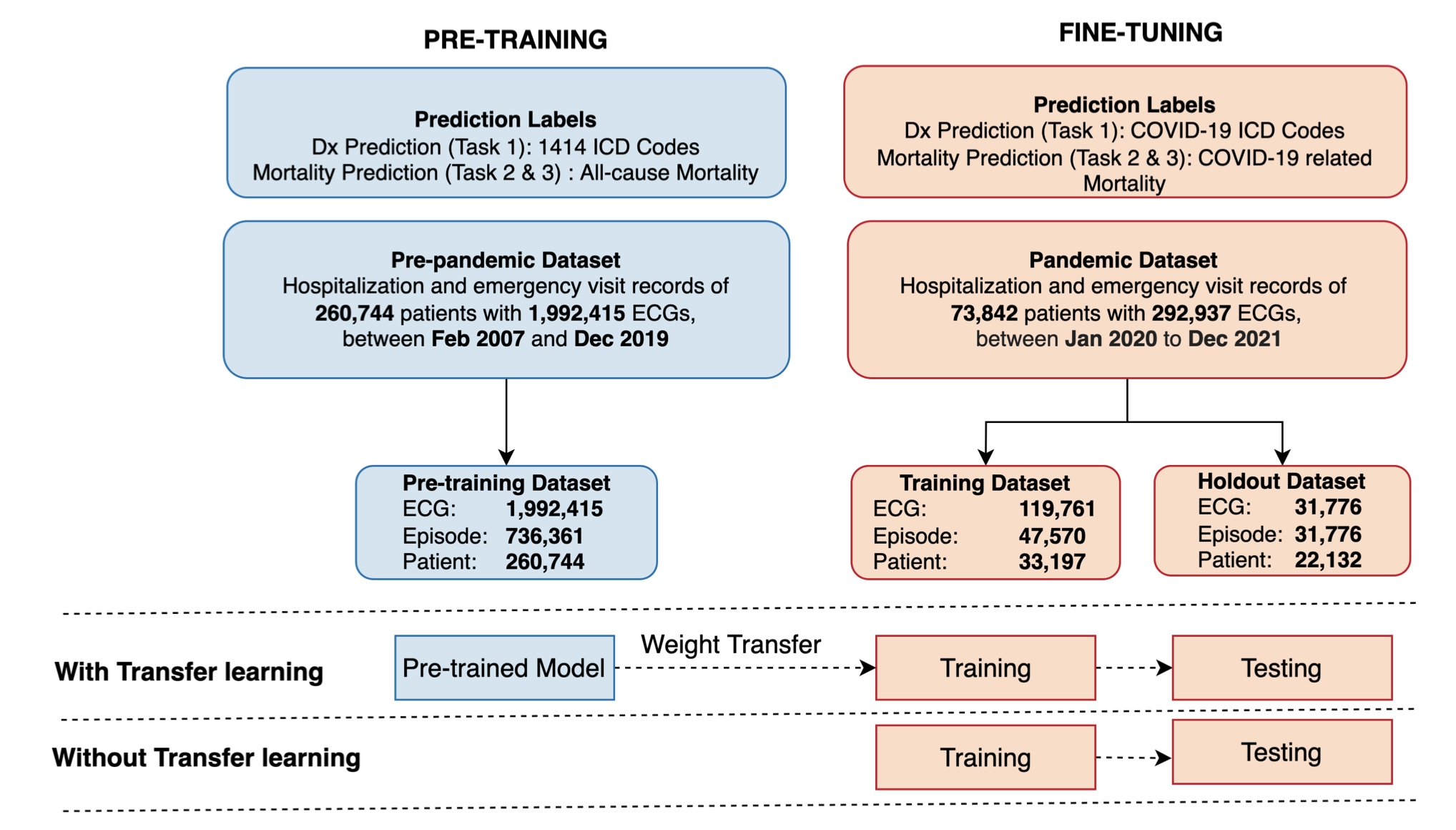
Improving ECG-based COVID-19 Diagnosis and Mortality Predictions Using Pre-pandemic Medical Records at Population-Scale
Weijie Sun, Sunil Vasu Kalmady, Nariman Sepehrvand, Luan Manh Chu, Zihan Wang, Amir Salimi, Abram Hindle, Russell Greiner, Padma Kaul
NeurIPS 2022 Workshop on Learning from Time Series for Health 2022
We show that pre-training deep learning models on pre-pandemic health records and fine-tuning them with limited pandemic data can substantially improve ECG-based COVID-19 diagnosis and prognosis. This transfer learning approach demonstrates notable gains across three prediction tasks, highlighting its potential for rapid AI deployment in future outbreaks.
Improving ECG-based COVID-19 Diagnosis and Mortality Predictions Using Pre-pandemic Medical Records at Population-Scale
Weijie Sun, Sunil Vasu Kalmady, Nariman Sepehrvand, Luan Manh Chu, Zihan Wang, Amir Salimi, Abram Hindle, Russell Greiner, Padma Kaul
NeurIPS 2022 Workshop on Learning from Time Series for Health 2022
We show that pre-training deep learning models on pre-pandemic health records and fine-tuning them with limited pandemic data can substantially improve ECG-based COVID-19 diagnosis and prognosis. This transfer learning approach demonstrates notable gains across three prediction tasks, highlighting its potential for rapid AI deployment in future outbreaks.
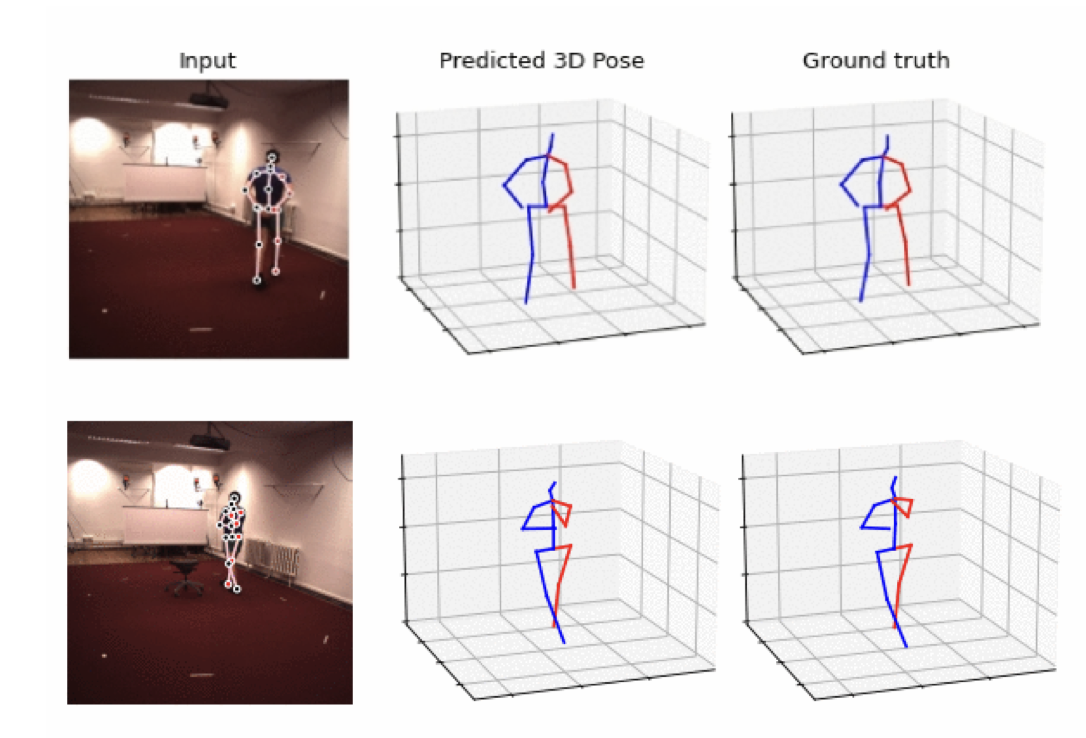
SPGNet: Spatial Projection Guided 3D Human Pose Estimation in Low Dimensional Space
Zihan Wang, Ruimin Chen, Mengxuan Liu, Guanfang Dong, Anup Basu
International Conference on Smart Multimedia 2022
We propose SPGNet, a method for 3D human pose estimation that integrates multi-dimensional re-projection into supervised learning. Our approach enforces kinematic constraints and jointly optimizes both 2D and 3D pose consistency, leading to improved accuracy. Experiments on the Human3.6M dataset show that SPGNet outperforms many state-of-the-art methods.
SPGNet: Spatial Projection Guided 3D Human Pose Estimation in Low Dimensional Space
Zihan Wang, Ruimin Chen, Mengxuan Liu, Guanfang Dong, Anup Basu
International Conference on Smart Multimedia 2022
We propose SPGNet, a method for 3D human pose estimation that integrates multi-dimensional re-projection into supervised learning. Our approach enforces kinematic constraints and jointly optimizes both 2D and 3D pose consistency, leading to improved accuracy. Experiments on the Human3.6M dataset show that SPGNet outperforms many state-of-the-art methods.